시각화 총 목차
1. 라이브러리 소개
2. 코드 한 줄로 만드는 시각화 보고서
3. 사용한 데이터셋
4. 가볍게 시작해보는 범주형 변수, 수치형 변수 시각화 예시
5. plot 종류
6. 시각화 시 주의할 점
7. 퀴즈
데이터분석 공부를 시작할 시기에, 시각화에 대해 배웠던 내용을 정리 및 공부한 글입니다. 총 목차 중 1~4 / 5 / 6~7로 나눠서 작성할 예정입니다.
1. 라이브러리 소개
자주 접하게 되는 시각화 라이브러리는 matplotlib 기반의 '정적 도구', JavaScript 기반의 '동적 도구'로 나뉩니다. 정적 도구는 이미지의 형태로 시각화합니다. 동적 도구는 그래프에 마우스를 올렸을 때 사용자의 목표에 따라 변화하는 데이터 수치를 보여줄 수 있습니다. 따라서, 동적 시각화는 interactive, dynamic visualization이라고도 불립니다.
- matplotlib 기반 정적 도구 : seaborn, pandas, plotnine 등
- JavaScript 기반 동적 도구 : plotly, bokeh, altair 등
| 라이브러리 로드 | API | |
| pandas | import pandas as pd | df.plot(kind=”bar”) |
| seaborn | import seaborn as sns | sns.barplot(data=df) |
| matplotlib | import matplotlib.pyplot as plt | plt.bar(df[”x축”], df[”y축”]) |
| plotly | import plotly.express as px | px.bar(data=df) |
1.1 Pandas
공식 사이트 : https://pandas.pydata.org/docs/user_guide/visualization.html
공부 사이트 : https://wikidocs.net/159927
Pandas는 matplotlib을 사용하기 쉽게 감싸두었습니다. Pandas 시각화의 특징은, plot을 붙여주는 간단한 방법으로 시각화를 할 수 있다는 것입니다.
1.2 matplotlib
공식 사이트 : https://matplotlib.org/
공부 사이트 : https://wikidocs.net/book/5011
matplotlib은 수학적 연산을 그래프로 표현해 준 라이브러리입니다. 데이터셋을 df라는 변수에 할당해서 사용한다고 했을 때, 위의 Pandas 에서 Pandas API 는 df.plot() 형태로 사용한다고 언급하였습니다. matplotlib API는 plt.plot(data=df)라는 형식으로 사용합니다.
1.3 seaborn
공식 사이트 : https://seaborn.pydata.org/
matplotlib을 기반으로 한 데이터 시각화 라이브러리로, matplotlib을 사용하기 쉽게 만들어줍니다. 기술이 잘 감추어져 있어 사용이 쉽다는 뜻인 ‘high-level interface’는 seaborn을 잘 나타내주는 특징입니다.
1.4 plotly
공식 사이트 : https://plotly.com/python/
공부 사이트 : https://wikidocs.net/book/8909 또는 https://plotly.com/python/time-series/ 에서 Range Slider, Candlestick, OHLC 예제 연습
plotly는 파이썬에서 제공하는 대표적인 동적 시각화 도구입니다. 동적 도구는 그래프에 마우스를 올렸을 때, 특정 데이터 수치를 확인해볼 수 있는 상호작용이 가능합니다.
1.5 깨알 정보
matplotlib
plt.show()를 출력했을 때, 길게 보이는 로그를 없애고 싶다면 코드 마지막에 / _ = ; 등을 붙여 실행하면 로그가 보이지 않습니다.
seaborn
처음 seaborn을 배울 때 흥미로웠던 이야기는 두 가지가 있었습니다. 첫 번째는, 왜 유난히 42란 숫자가 많이 보일까요? 파라미터 중 random_state = 42 로 설정하는 것은 랜덤의 seed 값을 고정시키는 역할을 합니다. 이 숫자는 더글라스 애덤스의 '은하수를 여행하는 히치하이커를 위한 안내서'에서 나왔습니다. 책에서 컴퓨터에게 묻는 인생의 본질에 대한 정답이 42였거든요!
두 번째는, pie chart에 대한 seaborn 라이브러리의 소신입니다. seaborn에서는 pie chart를 제공하지 않습니다. pie가 잘게 쪼개지면 값 차이를 시각적으로 보기 어렵고, seaborn에서는 다른 그래프로 대체될 수 있기 때문에 앞으로도 계획이 없을 것이라고 합니다. pie 차트가 너무 사용하고 싶다면, Pandas에서 df["dataset"].value_counts().plot(kind="pie") 방법을 사용하거나, 다른 시각화로 변형하면 됩니다.
plotly
seaborn과 비슷한 사용법이지만, 파라미터에서 hue 대신 color를 사용하는 것 잊지 맙시다!
2. 코드 한줄로 만드는 시각화 보고서
추상성이 있다는 것은 파이썬으로 감싸서 간단하게 만들어줬다는 뜻입니다. Pandas-profiling, sweetviz, autoviz 는 모두 짧은 코드로 기본적으로 봐야 하는 기술통계 값을 시각화합니다. 이렇게 편리한 추상화 도구들이 있지만, 직접 시각화를 하고 기술통계를 구하는 이유는, 대용량 데이터에 사용하기 어렵다는 단점 때문입니다. 아래는 df=sns.load_dataset("mpg")코드로 mpg 데이터셋을 df라는 변수에 담아 시각화 보고서를 만든 예시들입니다.
2.1 Pandas-profiling
| Pandas-profiling | !pip install pandas-profiling==3.1.0 from pandas_profiling import ProfileReport profile = ProfileReport(df, title="Profiling Report") profile.to_file("pandas_profile_report.html") https://github.com/ydataai/pandas-profiling |

2.2 Sweetviz
| Sweetviz | !pip install sweetviz import sweetviz as sv my_report = sv.analyze(df) my_report.show_html() https://github.com/fbdesignpro/sweetviz |

2.3 autoviz
| autoviz | !pip install autoviz from autoviz.AutoViz_Class import AutoViz_Class AV = AutoViz_Class() https://github.com/AutoViML/AutoViz |

3. 사용한 데이터셋
시각화를 그려보는 처음 단계에서는 앤스컴콰르텟 데이터셋, mpg 데이터셋을 추천합니다. 그 후 타이타닉, 피마인디언 데이터셋으로 많이 연습해봅니다.
3.1 앤스컴콰르텟(Anscombe's quartet)
앤스컴콰르텟은 shape값이 (44,3)인 데이터셋입니다. 불러오는 방법은 seaborn 라이브러리를 import하여 내장된 데이터셋을 불러오는 방법과, read_csv를 사용해서 불러오는 방법입니다. 해당 데이터셋에 관한 자세한 설명은 아래 두 링크를 통해 배경지식을 얻는 것을 추천합니다.
앤스컴콰르텟 데이터셋을 이용하여 seaborn 시각화(countplot, barplot, boxplot, violinplot, scatterplot, regplot, lmplot)을 연습했었습니다.
링크 1 : seaborn 활용 코드 예시 https://seaborn.pydata.org/examples/anscombes_quartet.html
링크 2 : 앤스컴콰르텟 데이터셋에 관한 설명 https://ko.wikipedia.org/wiki/앤스컴_콰르텟
# df = sns.load_dataset("anscombe")
df = pd.read_csv("https://raw.githubusercontent.com/mwaskom/seaborn-data/master/anscombe.csv")
df.shape
3.2 mpg
mpg는 mile per gallon, 즉 자동차 연비에 관한 데이터셋입니다. shape 값이 (398, 9)로 앤스컴콰르텟 연습 후, 조금 더 큰 데이터셋을 연습하고 싶을 때 좋습니다. 아래 시각화 예시들은 모두 mpg 데이터셋으로 진행 예정이기 때문에, 컬럼에 대한 설명을 남깁니다.
mpg : 연비 / cylinders : 실린더 개수 / displacement : 배기량 / horsepower : 마력 / weight : 무게 / acceleration : 엔진이 초당 얻을 수 있는 가속력 / model_year : 출시 년도 / origin : 제조 장소(미국USA, 유럽EU, 일본JPN), name : 자동차 이름
df = sns.load_dataset("mpg")
4. 가볍게 시작해보는 범주형 변수, 수치형 변수 시각화 예시
시각화를 할 때, 범주형 변수와 수치형 변수에 따라서 어느 plot이 적합할 지는 시각화를 처음 해본다면 모두 고민해보는 부분입니다. mpg 데이터셋으로 연습을 해보겠습니다.
변수를 알아보기 위해서는 두 가지 과정을 거칩니다. 먼저, df.info()로 각 변수의 타입을 알아봅니다. 다음으로, df.describe(include=”object”)와 같이 include나 exclude를 사용해서 어떤 컬럼이 범주형과 수치형에 해당하는지 알아봅니다. 보통 float와 int는 수치형 데이터, object 타입은 범주형 데이터로 판단을 하고 시각화를 진행합니다.

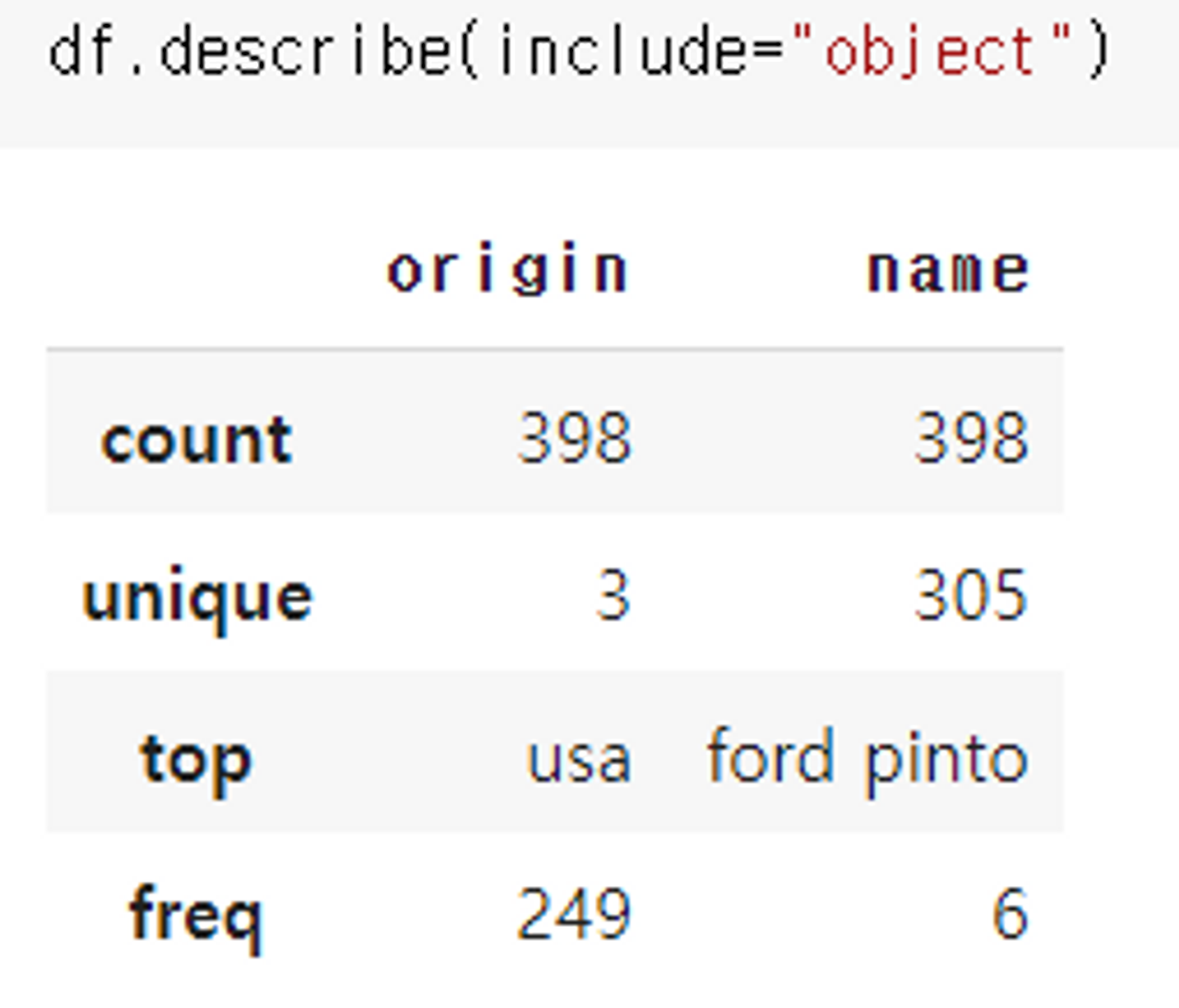
하지만, mpg 데이터셋은 cylinders와 model_year라는 우리를 헷갈리게 하는 변수가 있습니다. df.hist()로 전체 수치변수에 대한 히스토그램을 그렸는데, cylinders와 model_year는 다른 수치형 변수들과는 다르게 이가 빠져있는 듯이 그래프가 그려집니다.
이유는, 두 컬럼 모두 양적인 개념이 아니고, 연산이 의미가 없는 데이터이기 때문입니다. 이처럼, 수치형인지 범주형인지 헷갈린다면 전체 히스토그램을 그려서 시각화 해보거나, 유니크 값이 몇 개(cylinders는 유일값이 5개인 변수)가 되는지 확인하는 방법으로 범주형인지 수치형인지를 확인합니다.

시각화를 할 때, 범주형과 수치형 데이터를 구분해야 하는 이유는, 아래 Tip들처럼 범주형과 수치형에 따라 적합한 plot 달라지기 때문입니다. 아래 예를 제외하고도, 분석을 하면서 각 데이터 타입에 따라서 어떤 plot을 적용할지는 많이 연습해보면서 풀어야 할 과제입니다.
Tip 1
countplot을 그릴 때는 변수를 하나로, x는 범주형 데이터여야 합니다. 수치형 데이터의 분포를 보고 싶다면 displot, 범주형 데이터의 분포를 보고 싶다면 countplot을 사용합니다.
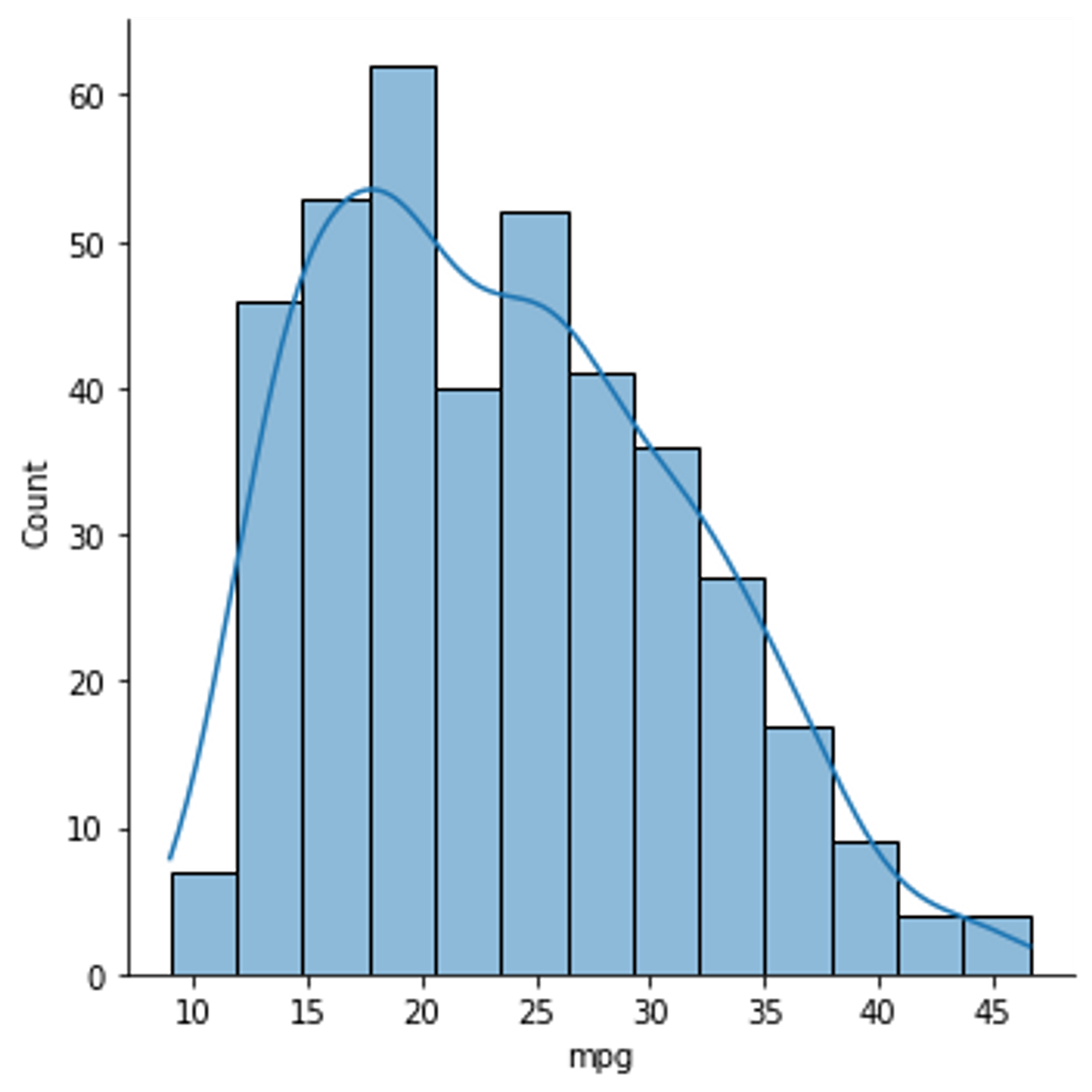

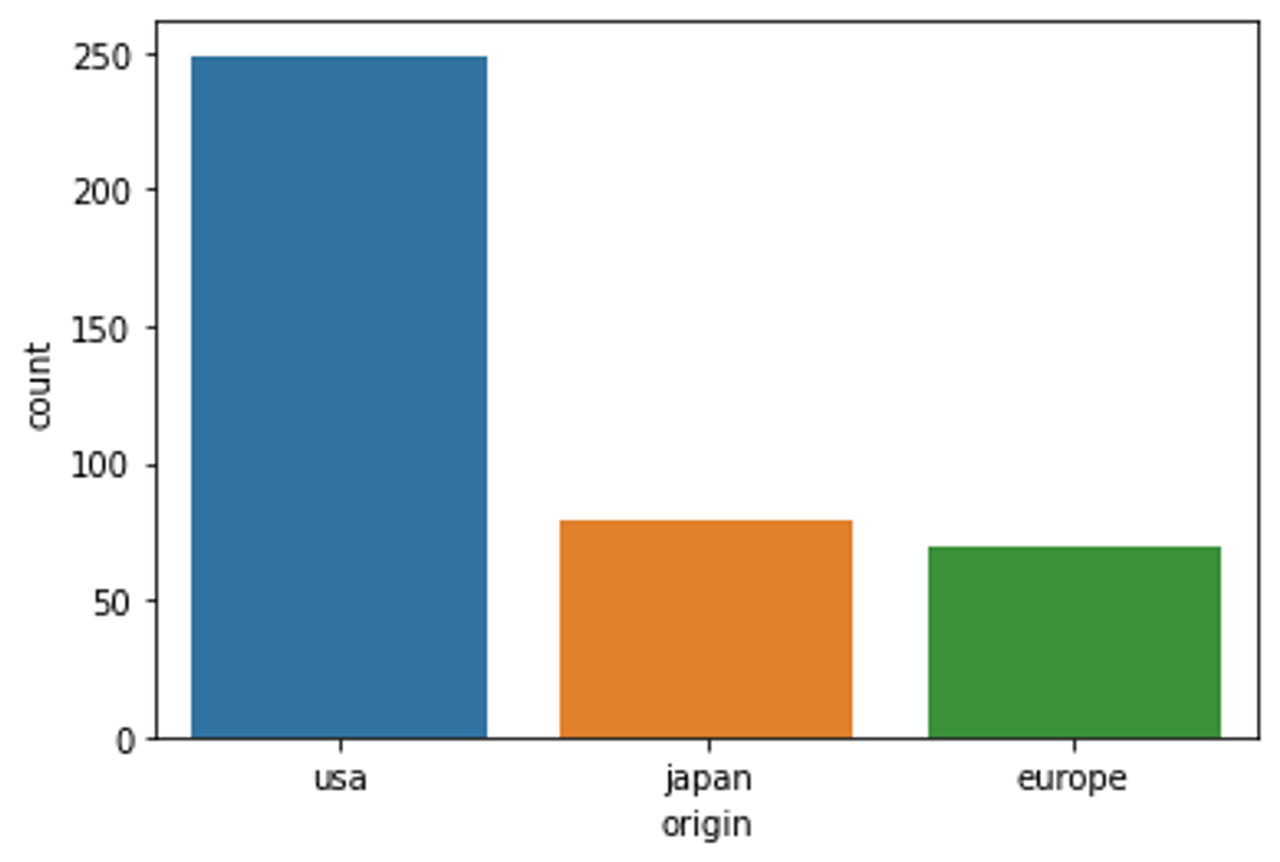

Tip 2
범주형 데이터일 때는 pointplot, 수치형 데이터의 경향성을 보고 싶을 때는 lineplot이 적절합니다.

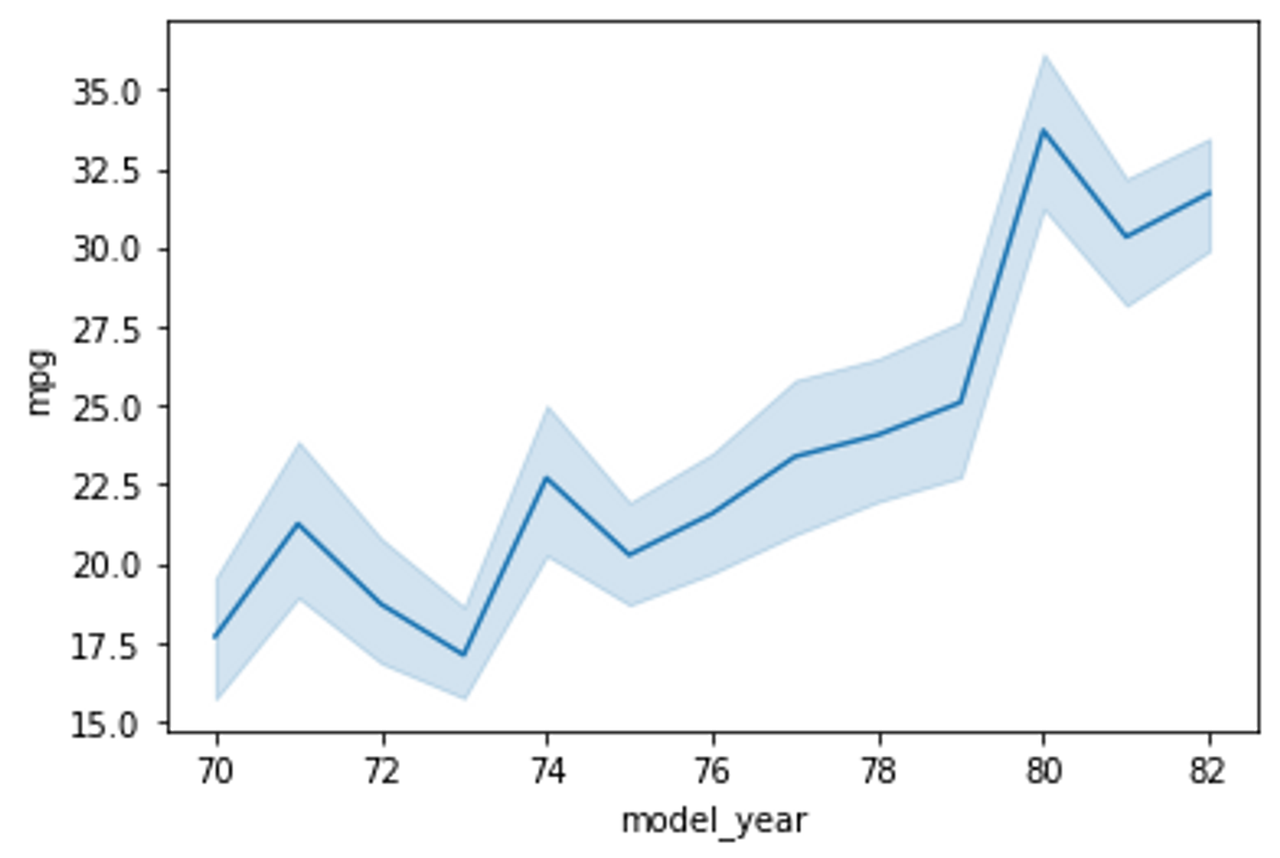
Tip 3
범주형 변수를 scatterplot으로 표현할 때는 점이 겹쳐서 빈도수와 변수 간 상관관계를 알기 어렵기 때문에, stipplot이나 swarmplot을 활용하여 빈도를 확인합니다.



Reference
1. AIS7 박조은 강사님 강의
2. 시각화 라이브러리
라이브러리 종류별 시각화 : https://zzsza.github.io/development/2018/08/24/data-visualization-in-python/
판다스 시각화 : https://wikidocs.net/159927
3. 라이브러리 개념 및 API 공식 사이트
4. 시각화 보고서
https://github.com/ydataai/pandas-profiling
https://github.com/fbdesignpro/sweetviz
https://github.com/AutoViML/AutoViz
5. 데이터셋 설명
앤스컴콰르텟1 : https://seaborn.pydata.org/examples/anscombes_quartet.html
앤스컴콰르텟2 : https://ko.wikipedia.org/wiki/앤스컴_콰르텟
6. 시각화 parameter
barplot : https://seaborn.pydata.org/generated/seaborn.barplot.html
errorbar : https://seaborn.pydata.org/tutorial/error_bars.html




댓글