평소에 궁금했던 것을 데이터로 가볍게 풀어보는 ‘월간 데이터노트’라는 채널에 참여했다. 25.01월에는 두 달 정도 기계식 키보드 구매를 위해 고민을 해왔는데 궁금한 요소가 많이 생겼다. 그래서 자연스럽게 월간 데이터노트 주제도 ‘기계식 키보드 트렌드’로 잡았다.
월간 데이터노트 소개 (모집글 정제)
문득 주변에 마주한 문제들을 데이터로 풀어보는,
<월간 윤종신>을 모방한 짧은 사이드프로젝트를 해보는 것.
공개된 API를 활용하면 쉽게 시각화 및 정보를 획득할 수 있다.
너무 큰 목표를 잡지 않고, 하루 혹은 반나절에 가능한 컨텐츠를 1-2장의 장표로 정리
1. 이 달의 호기심
키보드를 사려고 보니, 키보드가 보편화 되고 종류가 다양해진 것 같다.
→ 분석 주제 : ‘네이버 쇼핑’ 리스트를 통해 키보드 트렌드 확인
→ 세부 확인사항
- 어떤 브랜드가 많이 있을까?
- 어떤 키보드가 많을까?
- 어떤 축이 많을까?
- 가격대 분포는 어떻게 될까?
2. 프로세스
2.1 구상
· 수집할 플랫폼 : 네이버 vs 유튜브
→ 네이버 API 사용이 더 익숙해서 네이버로 먼저 시도
→ (회고) 오히려 기계식 키보드 관련 정보를 얻을 때는 유튜브 타건 영상 또는 키보드 리뷰 영상을 많이 본다고 느끼기 때문에 네이버와 유튜브로 수집한 결과가 차이가 날 지 궁금하다.
· 수집할 사이트 : 네이버 쇼핑 vs 네이버 블로그
→ 가격대 분포까지 보고 싶기 때문에 네이버 쇼핑 선택
→ (회고) 네이버 블로그로 소비자의 감성분석이 가능하나, 트렌드 파악에는 판매되는 제품을 먼저 볼 필요가 있다고 판단했다. 고객 분석을 해야 하는 곳에서는 목적에 맞는 수집 사이트 설정도 중요하겠다는 생각이 들었다.
· 검색 키워드 : ‘기계식 키보드’ 단일 검색어 vs 검색어 세분화
→ 1차적으로 단일 검색어로 파악 후 다음 스텝 설계
2.2 수집
네이버쇼핑 API 사용, 총 1,000개 데이터 수집

2.3 전처리
· brand, maker 컬럼 활용해 브랜드 확인 컬럼 생성
brand나 maker 값 중 하나만 있는 경우가 있거나, maker 컬럼의 null 값이 인식이 안되기 때문
brand(813개), maker(749개), 신규생성컬럼(834개)
· title 컬럼에서 ‘축‘ 정보 분리해 축컬럼 생성
title 컬럼에 축 정보가 있는 데이터 1,000개 중 457개
3. 시각화로 확인하기
3.1 어떤 브랜드가 많이 있을까?
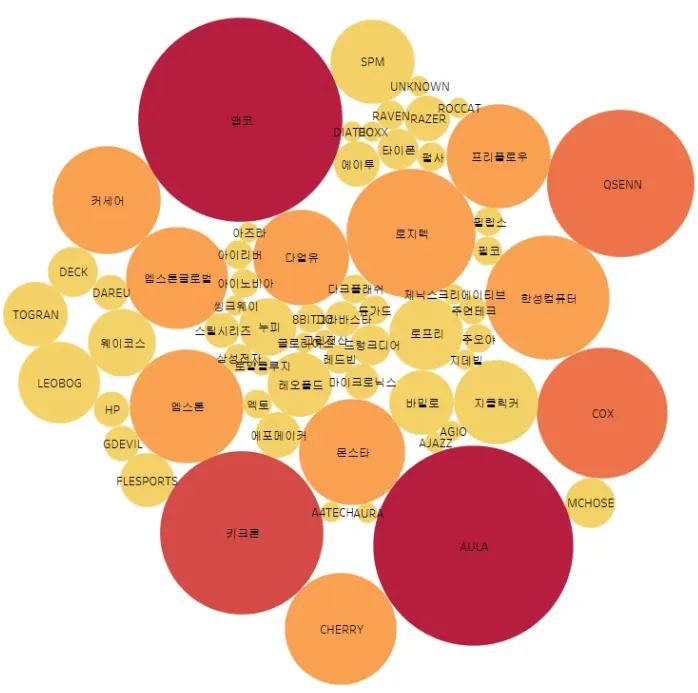
· 1순위 : 앱코(100건), AULA(96건)
· 2순위 : 키크론(64건)
· 3순위 : QSENN(52건), COX(41건)
· 4순위 : 로지텍(40건), 한성컴퓨터(37건), 엠스톤(31건), CHERRY(30건), 커세어(28건), 몬스타(27건), 프리플로우(26건), 엠스톤글로벌(25건), 다얼유(22건)
→ 역시 AULA.
하지만, 4순위 내에 인기 있다고 생각한 바밀로, 로프리, FLESPORTS, 씽크웨이, 에포메이커 등의 브랜드가 없다.
→ 쇼핑 데이터의 건수로 인기 브랜드를 확인한다는 방식은 맞지 않다고 느낀다.
3.2 어떤 축이 많을까?
1,000개 중 축 데이터는 543개
중복 제거 시, 축 종류 114개
· 순위 : 적축(59개), 갈축(23개), 저소음밀키축(19개), 청축(17개), 황축(16개), 저소음적축(15개), 자석축(15개),
클라우드축(11개), 저소음바다축(11개), 민트축(11개) 등
→ 축 종류가 다양하다는 것은 확인
→ 3.1 과 동일하게, 쇼핑 데이터 건수로 축의 인기도를 확인하는 방식은 맞지 않다고 느낀다.
→ 전처리 판단이 필요한 요소 : 한 제품에 ‘홍축, 청축, 갈축, 흑축‘과 같이 여러 축이 적혀 있는 경우
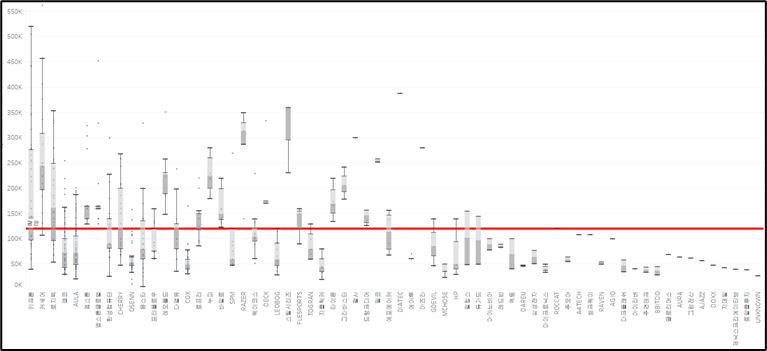
3.3 가격대 분포는 어떨까?
평균 가격대 119,410원
→ boxplot의 꼬리가 길다 를 한 브랜드가 다양한 가격대의 제품을 보유하고 있다 or 데이터의 변동성이 많다 or 허수 가격이 많다 or 이상치를 많이 가지고 있다 등 해석의 여지가 다양하다.
4. 마무리
4.1 회고를 빙자한 생각 남겨두기
· 수집할 플랫폼, 플랫폼 내의 사이트 중 목적에 맞는 사이트 선정, 검색 키워드 등 분석 진행 전 설정해둬야 할 사항이 많구나.
· 너무 적은 데이터를 수집했나? 하지만 쇼핑사이트에서는 수집 데이터의 개수가 늘어난다고 정확성이 높아지는 것은 맞나? 쇼핑 데이터 건수가 많다고 인기 브랜드, 인기 키보드, 인기 축이라고 할 수 있을까? 1000개 데이터 중 브랜드 정보를 가진 데이터는 83%, 축 정보를 가진 데이터는 45%인데 이게 트렌드를 말한다고 볼 수 있을까? null 값이 많은데 신뢰할 만한 결과일까?
· (전처리) 광고 태그는 제거를 놓쳐서 아쉽다.
· (전처리) 엠스톤, 엠스톤글로벌은 하나로 취합할 것인가, 따로 둘 것인가?
· (시각화) 브랜드 시각화는 막대나 표가 더 나았을까?
· (피드백) 3.1의 결과에 대해 해외구매를 해야 하는 경우는 잘 안잡힌 것 같다는 의견을 들었다. 이 의견대로라면 확실히 유튜브로 분석을 진행하면 상이한 결과도 나올 수 있겠다.
4.2 재미요소
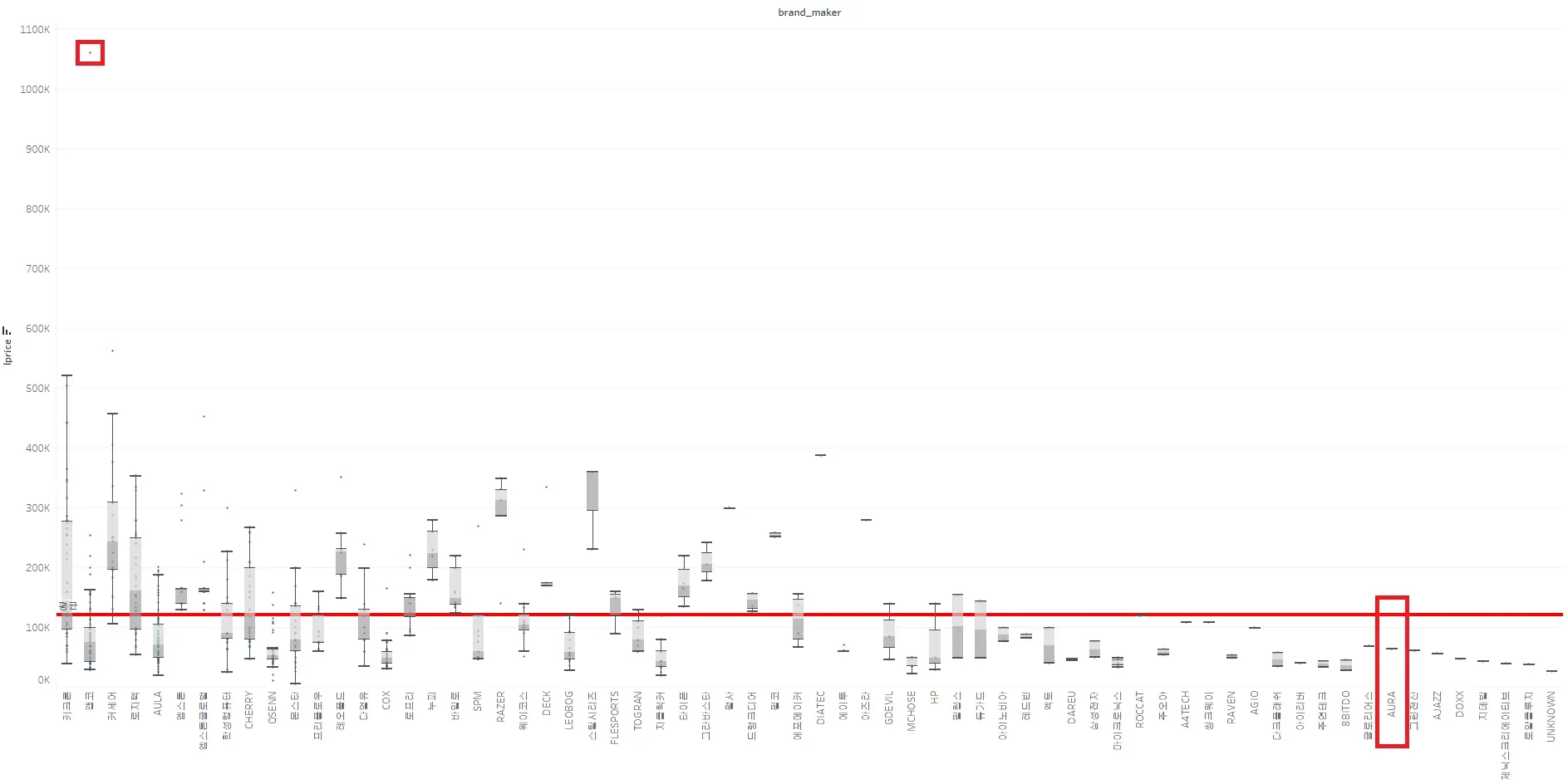
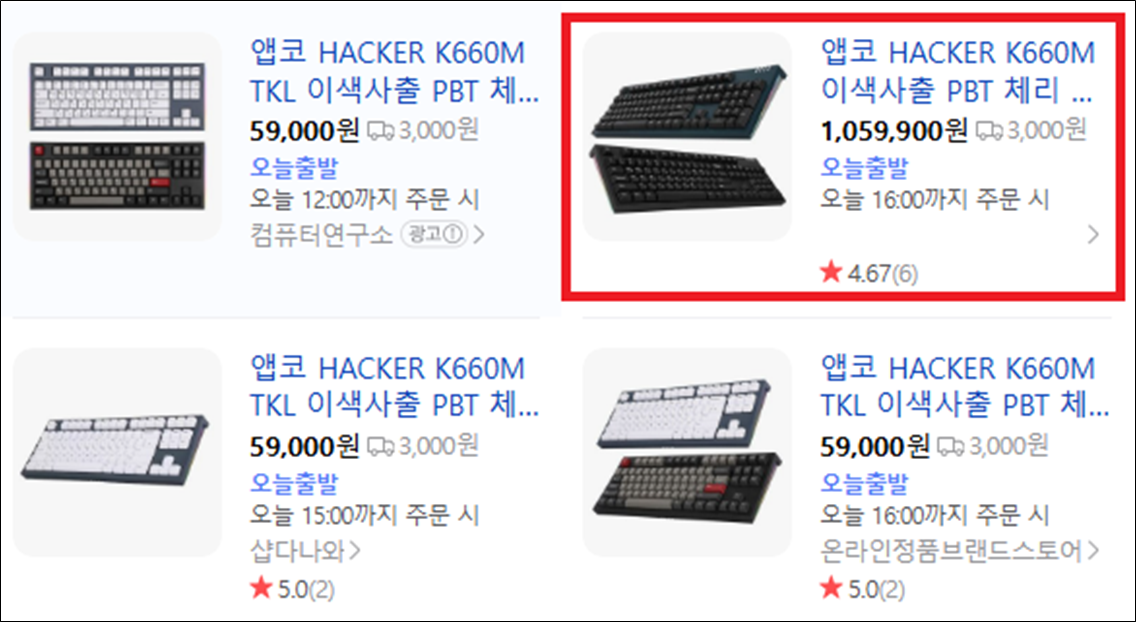
· 키크론이란 브랜드의 1,059,900원이라는 금액 이상치 확인하기
→ 6만원대 키보드이지만, 해당 제품을 더 이상 판매하지 않아 금액을 올리는 방식으로 해당 쇼핑몰에서 구매금지 처리를 한 것으로 추정
· AULA를 AURA로 maker 등록을 한 경우
5. 참조
네이버 쇼핑 API 1 https://velog.io/@masew8/네이버-API를-활용해-원하는-상품-정보를-검색하고-엑셀로-저장하는-방법
네이버 쇼핑 API 2 https://velog.io/@jj_study/프로젝트-네이버-쇼핑-검색-API




댓글