DB를 연결해서 SQL 쿼리를 날리기 위해서는 DBMS 툴(ex. Oracle SQL Developer, DBeaver 등)을 사용할 것이다. 그런데, 굳이 DBMS 툴을 사용하지 않고, 파이썬에 DB를 연결해 작업할 일이 있을까?
1. 배경1 : 파이썬에 DB를 연결한다는 게 무엇인가
여기서 파이썬에 DB 연결이라는 것은, 크게 두 가지로 해석될 수 있다.
첫 번째는, VS Code를 Oracle SQL Developer처럼 쓰는 것이다. (엄밀히 말하면 VS Code는 파이썬이 아니지만..)
이 경우에는 Oracle SQL Developer Extension for VSCode를 설치해 사용하면 된다. 그럼 VS Code에서 Oracle SQL Developer처럼 좌측 또는 우측에 테이블이 보이고, 편집창에서 쿼리를 날려 실행한다. 말 그대로 VS Code를 Oracle SQL Developer처럼 쓰는 것과 같다.

두 번째는, VS Code에서 DB 데이터를 데이터프레임으로 불러온 후, 파이썬을 활용해 추가 작업을 하는 것이다. 파이썬 코드 작업이라고 하면, SQL보다 파이썬에서 훨씬 수월하게 처리할 수 있는 전처리나 시각화, 데이터 변환, 멀리 나가면 ML 활용 등을 의미한다.
2. 배경2 : 파이썬이 SQL 보다 편해?
오늘 작성할 내용은 두 번째인 VS Code에서 DB 데이터를 파이썬으로 처리하는 작업에 관한 내용이다. SQL과 파이썬은 편하게 사용할 수 있을 때가 조금 다르다고 생각한다.
2.1 SQL이 편하다고 느낀 경우
두 가지 테이블(또는 데이터프레임)을 매칭해서 일치 여부를 판가름 할 때는, 파이썬의 merge 보다는 SQL의 JOIN 기능이 편하다고 느꼈다.
2.2 파이썬이 편하다고 느낀 경우
전처리가 복잡해질수록 파이썬이 편리했다. 데이터프레임에서는 간단한 코드 몇 줄로 해결할 수 있는 작업이, SQL에서는 여러 줄의 쿼리로 길어지곤 했다. 특히, 들여쓰기가 많은 경우, 한 번의 들여쓰기 실수로 쿼리가 꼬이면 수정하는 데 시간이 걸렸다.
3. 발단 : 데이터를 산출할 때 SQL로만 하는 것 vs SQL + 부수적인 작업이 필요한 경우
두 번째를 시도하려는 이유는, 자동화 업무 중 수정 요청이 들어왔을 때 발생하는 지연 상황 때문이었다. 그리고, 지연 상황을 해결하려면 파이썬에서 작업하는게 해결책이 되지 않을까?라는 생각 때문이다.
보고의 자동화는 보통 '쿼리 작성 → 자동화팀이 산출된 데이터로 자동화 로직 설계 → 보고' 로 이뤄진다. 하지만 요구사항이 조금씩 바뀔 때마다 수정을 하려면 '쿼리 수정 → 수정 후 산출된 데이터 검토 → 자동화팀에 수정 요청 → 대기 → 자동화 로직 수정 → 보고' 의 단계를 거치게 된다. 빠른 대응이 필요할 때도 지연이 되는 경우가 생긴다.
여기서 지연이 발생하는 주요 원인은 두 가지였다.
1. 복잡한 쿼리가 꼬이지 않게 건드리면서 수정
- 쿼리를 작성한 사람이 아니면 뜯어보는데 걸리는 시간도 발생할 수 있음
- 빠르게 수정사항을 반영하기 위해, 쿼리의 성능보다는 구현에 초점을 맞춰 쿼리는 누더기가 될 수 있음
2. 여러 부서가 얽혀 있으면, 각 팀의 업무 우선순위에 따라 대기 시간이 길어질 수 있음.
- 자동화팀은 쿼리가 수정되는 동안 대기
- 보고하는 팀은 자동화팀의 로직 수정 동안 대기
시도해보자!
1. 쿼리를 복잡하게 만들어서 유지보수하기 어렵게 하지 말고, SQL은 가볍게 작성하고 → 복잡한 전처리는 파이썬 코드로 처리하면 수정이 더 편하지 않을까?
2. 여러 부서 간 대기가 문제라면, 자동화팀이 로직을 수정하지 않아도 되도록 최대한 최종 결과물 형태로 데이터를 가공해서 전달하자!
로직 수정이 필요한 경우 : 코드 실행 → 엑셀로 다운로드 → 엑셀에서 보고 양식대로 작업(자동화팀) → 보고
로직 수정이 필요 없는 경우 : 코드 실행 → 파이썬에서 전처리 후 보고 양식대로 작업된 것을 실행(자동화팀) → 보고
4. 환경 구축 시작 : VS Code에 Oracle SQL Developer 연결
사전 준비물
- Oracle SQL Developer : 사실 DBMS 툴이 필요하기 보다, DBMS 툴에 연결하던 사용자 정보가 필요
- VS Code : 파이썬을 사용하기 위한 툴
4.1 pip install oracledb
oracledb 란 파이썬으로 oracle DB에 연결해서 DB 작업을 할 수 있도록 도와주는 라이브러리이다. 기존에 사용되던 cx_Oracle 설치방법이 보편적으로 작성되어 있지만, cx_Oracle package가 업그레이드 된 것이 oracledb package로 보인다. (25.01월 기준 pip install cx_Oracle 시, 설치 실패)
1) anaconda prompt 를 관리자권한으로 실행
- anaconda를 설치해 쥬피터나 파이썬 등을 사용하고 있으므로, pip install 시 anaconda prompt를 관리자권한으로 실행해 설치를 진행
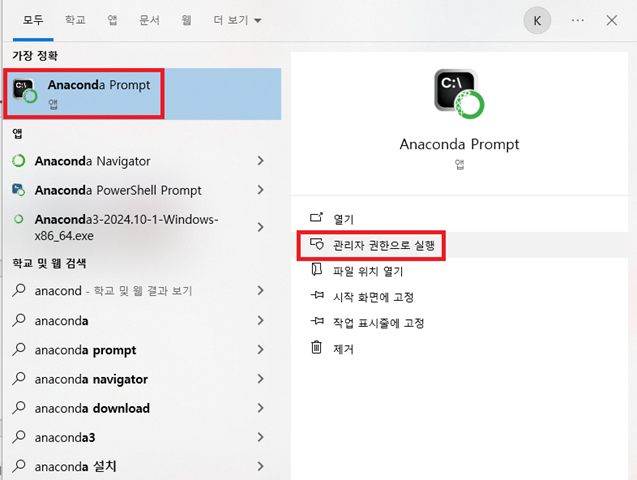
2) 이 때, 관리자권한으로 실행 후 뜬 창에서 (base)로 연결이 된 경로가 뜬 후 명령어(pip install oracledb) 입력
- (base)가 안뜨면 아나콘다 환경이 활성화되지 않은 상태이기 때문에, 아나콘다 패키지가 아닌 기본 파이썬이 사용되어 설치될 수 있다.

3) import oracledb
설치 완료 후, import 가 정상적으로 되는지 코드 작성 후 실행
4.2 오류 해결 - instant client 파일 다운로드
import 후 instant 파일을 설치하지 않고 실행하면, thin mode에서는 지원이 안된다는 오류 메세지가 뜬다. thick mode 에서 수행하기 위해 instant 파일을 아래 링크에서 다운로드하여 설치한다.
https://www.oracle.com/database/technologies/instant-client/downloads.html
여기서 thin mode란, 오라클 데이터베이스 서버 버전이 12.2 이상이며, instant clinet 설치가 필요 없다.
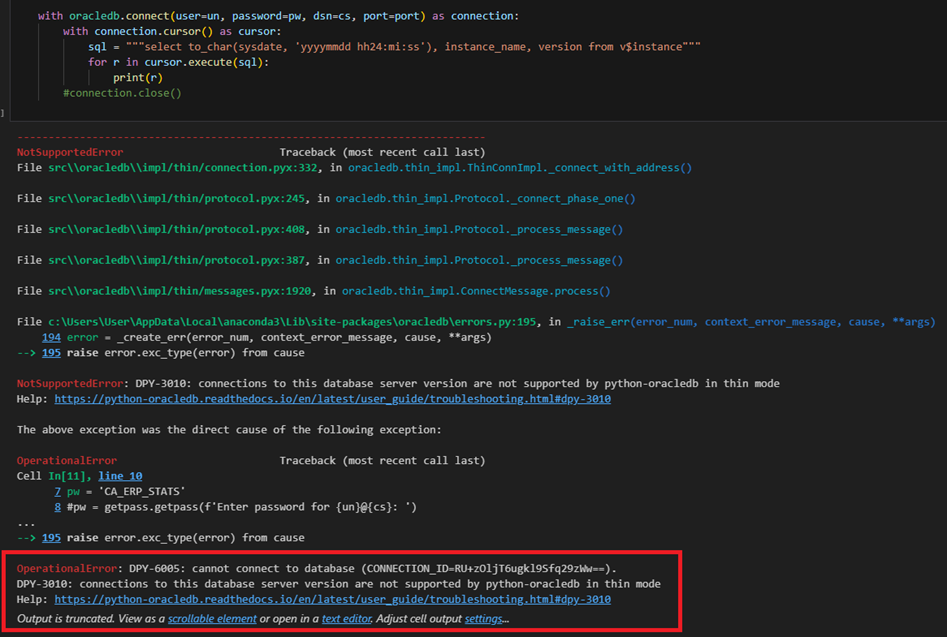

4.3 VSCode에서 DB 에 접속 테스트
instant client 파일을 받아 오류를 해결하고, import oracledb가 잘 되는지 확인했다면, DB에 연결이 잘 되는지도 테스트를 해본다.
import oracledb
# 인스턴트 클라이언트 경로 설정
# 바탕화면에 인스턴트 클라이언트 파일을 압축해제 했기 때문에 아래와 같은 경로
# 설치한 경로에 따라, 인스턴트 파일 버전에 따라(instantclient_23_6) 경로는 달라질 수 있음
Oracledb.init_oracle_client(lib_dir=r"C:\Users\User\Desktop\instantclient_23_6")
# 기본 DB 접속 정보 설정
# oracle sql developer 에서 데이터베이스 접속 창을 눌렀을 때 뜨는 창의 사용자정보, 세부정보를 입력
# 회사에서는 SID가 아닌 서비스 이름을 사용
username = “Oracle SQL Developer 접속 시 사용하는 사용자이름”
password = “Oracle SQL Developer 접속 시 사용하는 비번”
host = “Oracle SQL Developer 접속 시 사용하는 서버주소 : 000.000.0.00 등의 형식”
port = “Oracle SQL Developer 접속 시 사용하는 포트”
service_name = “서비스 이름”
# dsn 연결
dsn = oracledb.makedsn(host, port, service_name = service_name)
# db 접속
con = oracledb.connect(user=username, password, dsn = dsn)
# 연결 확인
print(“연결성공”)
↓ 기본 DB 접속 정보 설정에 들어갈 데이터를 보는 곳(Oracle SQL Developer 기준)


4.4 VSCode에서 접속된 DB 데이터 가져오기 테스트
DB에도 연결이 잘 되었다면, 이제 VSCode에서 처리할 데이터를 데이터프레임으로 불러오는 작업도 테스트를 해본다.
# 커서는 데이터베이스 상호작용을 관리하는 인터페이스, SQL 쿼리 실행 및 결과 관리를 담당
cursor = con.cursor()
import pandas
query = ‘SELECT * FROM 테이블명 WHERE ROWNUM <= 10’ # 데이터 양이 많으면 시간이 걸려 테스트용으로는 임시로 10개만 출력
df = pd.read_sql(query, con=con)
print(df.head())
5. 남은 과제 : 그래서, 뭐가 더 효율적이었어?
이제 겨우 환경 구축이 끝났다. 불러온 데이터프레임을 전처리를 하는 코드를 작성하고, SQL에서 모든 작업을 하는 것보다 파이썬 코드를 작성하는게 효율이 좋은지 테스트를 해야 한다.
효율성이 향상되었는지를 판단하려면, 기존 방식과 새로운 방식의 속도를 비교해야 한다. 하지만 "반나절 걸렸다" 같은 대략적인 감은 잡을 수 있어도, 이를 정확히 정량화하는 것은 쉽지 않다.
각 방식을 어떻게 정량적으로 바꿔서 효율을 측정할까 는 고민으로 남는다.
6. Reference
cx_oracle 관련 처음 본 글 https://blog.naver.com/regenesis90/222352911646
이 글로 오류 고침 https://thisiswhoiam.tistory.com/57
cx버전 예시 https://kyounggu.tistory.com/28
oracledb 버전 예시 https://velog.io/@minjee98/Database-oracledb-파이썬으로-오라클-연동

댓글